
热门主题





聪明人的笨功夫 -- MesaTEE安全形式化验证实践
2019-08-08 16:21:5914566人阅读
各类TEE(例如TPM和Intel SGX)提供了强大的可信计算硬件基础,但他们并不直接保证软件的安全性。诸如缓冲区溢出等内存安全问题为攻击者提供了侵入TEE的可乘之机。因此,软件内存安全保护极其重要。MesaTEE(源自“Memory Safe TEE”)除了遵循混合内存安全模型(Hybrid Memory Safety)用Rust等内存安全语言重构关键组件,还对其他的C/C++代码进行了静态扫描、动态测试和形式化验证。
静态扫描通过分析程序编码模式,能快速报出浅层漏洞,但会有相对较高的误报和漏报;以模糊测试(Fuzzing)为代表的动态测试通过提供随机改变的输入来触发问题,准确率高,但很难完整覆盖程序的所有状态,难以证明程序是无缺陷的。因此在高安全需求场景下,静态扫描和动态测试是不够的,需要形式化验证用严格的数学方法推演程序的完整状态空间符合安全设计规范,证明程序在设立条件下一定不会出问题。因此形式化验证是安全实践里非常重要的一环。
百度安全实验室在云计算、区块链、自动驾驶等工业级场景的部署里都有形式化验证的实践。例如在MesaTEE TPM项目里,形式化验证对TPM核心软件栈(tpm2-tss 2.1.0版本)进行了验证,保证了该项目约6.7万行代码在MesaTEE调用场景下不会出安全问题。验证期间发现并修复空指针引用、越界读写、内存泄露等等多种共计140+处安全缺陷,验证过的tpm2-tss版本发布在了GitHub上(https://github.com/mesalock-linux/tpm2-tss-verified)。除此之外,在内存安全的Python解释器MesaPy项目里,形式化验证保证了C backend的代码在MesaPy所有使用场景下是内存安全的。验证期间发现并修补了包括空指针引用,整数溢出等14处安全缺陷,验证方法和结果也发布在了GitHub上(https://github.com/mesalock-linux/mesapy/tree/mesapy2.7/verification)。
一.形式化验证介绍
形式化验证是指使用严格的数学方法来推理验证程序是否符合安全规范的过程。该方法具体包括源码准备、基于抽象解释(Abstract Interpretation [1] [2] [3],下文简称AI)的值域分析(Value Analysis)、最弱前置条件验证(Weakest Precondition)和程序缺陷报告等阶段。如下图所示。
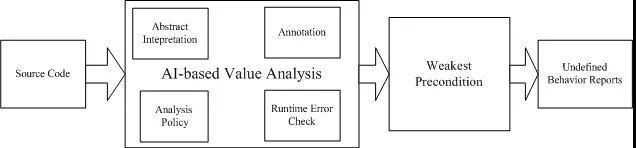
图1 形式化验证方法流程
1.1 源码准备
理想情况下,形式化验证需要在程序的完整代码上进行。这里不仅包括目标程序本身的源代码,还需要依赖的第三方库的源代码。然而很多情况下第三方库没有给出源码,或者第三方库的源码过于庞大无益于关注程序主体的安全性,这种情况可以对项目中调用依赖库的函数写抽象描述辅助验证。
接下来是要确定需要验证的目标函数,为目标函数写测试用例。形式化验证任务中,测试用例中的函数参数用Interval表示,来覆盖所有可能取值。同时,还要覆盖到函数调用的所有场景,如下面示例:

我们可以从项目自带的Unit Test和Integration Test入手,来编写Interval版本的测试用例。这两类测试用例一般会涵盖项目中关键函数和关键功能逻辑,从这里入手能够覆盖验证目标,保证验证质量。
1.2 基于抽象解释的值域分析 (Abstract Interpretation Based Value Analyis)
在这个阶段中,分析人员对源代码的标注(Annotation),配置分析策略(Analysis Policy),然后依赖抽象解释(Abstract Interpretation)技术来执行执行值域分析(Value Analysis)。分析引擎会对标注的源码进行分析,插入运行时错误检查(Runtime Error Check)语句标注,分析程序控制流、数据流并计算程序中变量的所有可能取值,验证标注属性的真假。分析过程中无法确认为真的标注属性所对应的语句归类为未定义行为(Undefined Behavior),在实际分析过程中,可能需要分析人员对Undefined Behavior加入额外的标注属性来消减误报。接下来,最弱前置条件分析引擎(Weakest Precondition)会验证这些人工额外标注,将最终发现的Undefined Behavior将呈报给分析人员,进行最后确认。
a. 抽象解释 (Abstract Intepretation)
抽象解释是指使用另一个抽象对象域(Abstract Domain [3])上的计算,来抽象逼近程序具体对象域(Concrete Domain [3])上的计算。抽象语义涵盖所有可能的情况,是具体程序语义的超集,因此如果抽象语义是安全的,那么具体语义也是安全的。每一个抽象对象域规定了抽象对象(或变量)之间的运算规则体系(Lattice)[3]。最常见的抽线对象域是Interval Domain [3],它的运算规则与具体数值计算规则相似(如下面示例所示)。由于Interval Domain易于理解并且计算复杂度不高,所以实际程序验证分析任务中采用Interval Domain来进行Value Analysis。

Abstract Interpretation对变量的计算推演可能存在Over-approximation [3]。原因是为了保证程序在合理时间内分析结束,分析引擎常常会扩展变量的值域,以减小计算复杂度。这样,由于变量值域扩大,在Runtime Error Check时可能由于它不在合法数值范围内而报告为Undefined Behavior,但实际上变量真实取值并没有超出合法范围。这种情况需要由稍后介绍的程序标注来消减误报。
b. 分析策略(Analysis Policy)
AI-based Value Analysis在计算推演过程中会记录变量的取值情况。随着程序分析的不断深入,变量的取值会随着程序分支而划分开来,在各自分支分别计算推演。最终会使得在某程序点上,变量取值出现很多种可能。理论上,对于任何程序,分析时保留变量的所有取值情况将会产生最为精准的结果,但是随之而来的是巨大的空间和时间开销,难以保证分析在合理的时间内结束。这时需要设定合理的分析策略,来实现分析消耗时间和分析结果精度的平衡。
我们用State来代表一个变量取值的所有可能。实际分析中,通常设定一个State Level,表示任意程序点允许保存变量状态的最大数量,如果某点处,变量所有取值情况的数量超过了设定,就需要合并状态。此外,变量之间关系记录的细致程度,也会对验证分析结果产生影响。这一点主要体现在函数之间相互调用时,子函数返回时如何记录多个返回变量State之间(函数有返回参数时认为有多个返回值)的关联关系(State Split)。下面的示例代码分别展示了State Level和State Split设定对分析结果的影响。

如果State Level限定很小(比如1),那么在L处,x取值为 x ∈ [1..9],y取值为 y ∈ [6..10]。但如果状态空间足够大(State Level大于等于2),那么x和y的取值会进一步细化,拆分为 y == 6 ⋀ x ∈ [1..4]或者 y == 10 ⋀ x ∈ [5..9]这两个状态。可见State Level越大,分析粒度越细,结果越精确。

上述代码中,当State Split的粒度设置较低时,在(3)处会报出“使用danlging pointer hd”的Undefined Behavior,原因是它认为在(2)处已经free掉了hd,(3)处不应该再使用。然而经过分析我们可以发现,(2)的free只有当(2)处err为true时才会执行。这种条件下,(2)处free执行后,(3)处分支根本不会执行。当State Split粒度调高时,Value Analysis会记录err和hd的关系,就不会产生误报。
虽然更高的State Level和更细致的State Split粒度能为我们带来更为准确的分析结果,但在程序代码量庞大而且逻辑复杂的情况下,这两个策略设置过高,可能导致分析无法在合理时间内结束。所以实际分析中,需要评估State Level和State Split,达到分析效果和分析时间的平衡。
c. 程序标注 (Annotation)
程序标注是利用形式化描述语言(如ACSL [3])来描述程序语义,辅助分析引擎生成验证约束。在实际的验证分析过程中,有时由于受限于分析粒度的设定,Value Analysis阶段无法产生十分精细的结果,产生Undefined Behavior的误报,这时就需要分析人员加入Annotation,辅助分析过程产生更准确的分析结果。而这些Annotation的正确性,也需要在下文的最弱前置条件验证中验证。
在下面例子中,假定没有配置很高的分析粒度,L1处x和y之间的大小关系不会被记录下来,在程序中L3处,会产生“x可能超出数组T的合法范围“的误报。如果,在L3处加入//@ assert 0 < x < 10这个约束,就可以引导分析过程来消除该误报。

除了assert,程序标注还包括函数合约(Function Contract)和循环不变式(Loop Invariant)等。函数合约描述函数的输入和输出的约束;Loop Invariant描述循环的约束,帮助Value Analysis更好的理解程序中复杂循环的语义,有助于消减分析过程中产生的误报。
d. 运行时错误检测(Runtime Error Check)
Value Analysis分析引擎会加入Runtiem Error Check要求程序符合特定属性。例如在下面示例中,在内存数据访问操作之前,value analysis会加入类似于/*@ assert ret: mem_access: \valid_read(); */对访问地址合法性判断的标注属性。如果内存地址的值域不在合法范围之内(比如为NULL),就报出Undefined Behavior。

1.3 最弱前置条件验证(Weakest Precondition)
函数合约和Runtime Error Check相关的标注属性在Value Analysis过程中验证。然而,有些assert标注是分析人员为了辅助Value Analysis加入的,例如//@ assert 0 < x < 10。这类约束条件,Value Analysis始终认为它们为真。为了确保这些约束条件自恰,必须单独对这部分约束进行验证。最弱前置条件(WP, Weakest Precondition)正是用来验证这些约束的。
Weakest Precondition [5]可以形式化描述为wp(S, R)。对于某程序位置P,S为从P处开始执行的语句,R为从P处执行语句S后所达到的约束条件(Postcondition)。wp(S, R)表达的含义是,在执行语句S之后,为了能让R符合特定的Postcondition,P处所需要满足的最弱前提条件。换言之,WP求解工具可以根据R和S,求解出P处要满足的最弱前提条件。
这样,对于每一个向Value Analysis提供的assert标注,通过WP都可以求得它的最弱前提条件。如果所有前提条件都能满足所在上下文的约束,就能得到自恰的保证。
二.案例分析
2.1 TPM 验证分析
我们用形式化验证的方法,借助形式化验证工具TIS [6]对若干工业级别的项目进行了分析实践。这些项目涉及云计算、区块链、自动驾驶等。其中,以TPM可信计算的核心软件栈tpm2-tss(https://github.com/tpm2-software/tpm2-tss)项目为例,我们验证了该项目2.1.0版本的代码,共验证了约1300个函数 / 约6.7万行代码,发现并修补了包括空指针引用、内存泄露,越界读写等在内的140+多处程序缺陷。下面是在验证过程中发现的程序缺陷(左图)和对应的修补方案(右图),这些程序缺陷均已经报给开发者并得到最终确认,并已在最新代码中修补。
示例1:空指针引用

示例2: 内存泄露
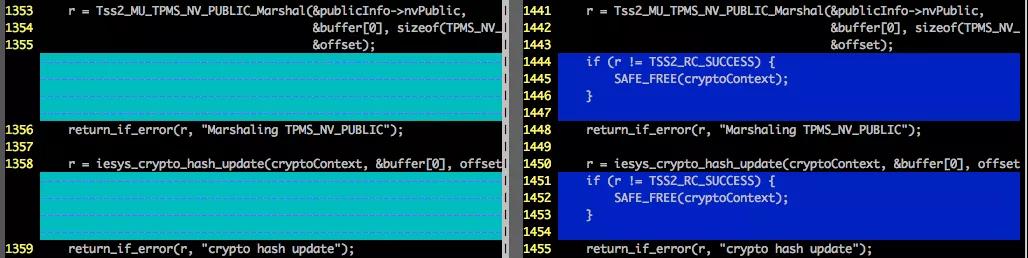
示例3:循环条件错误导致数组越界读
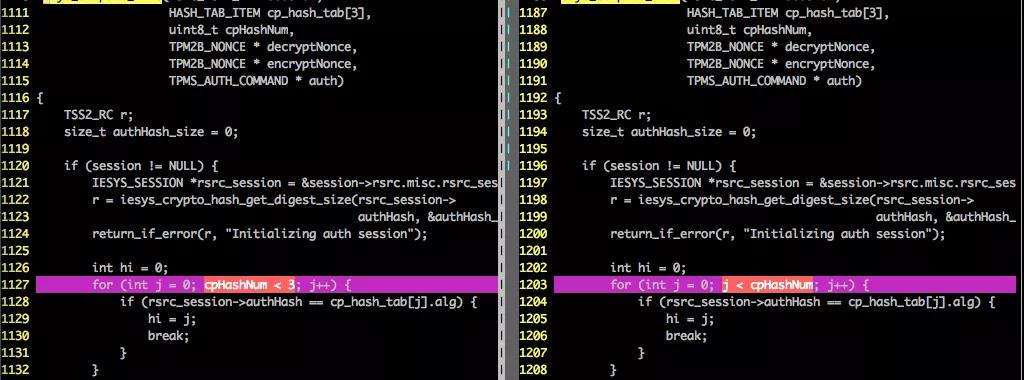
示例4:free错误导致内存破坏
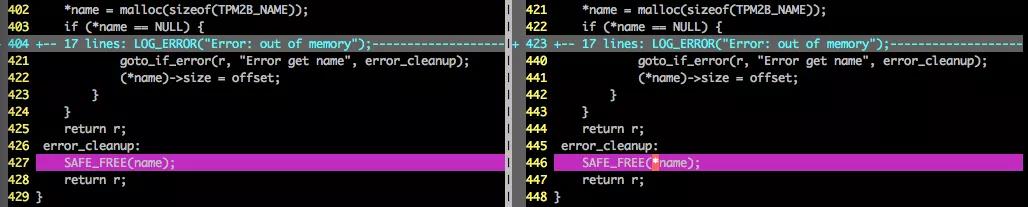
2.2 Mesapy 验证分析
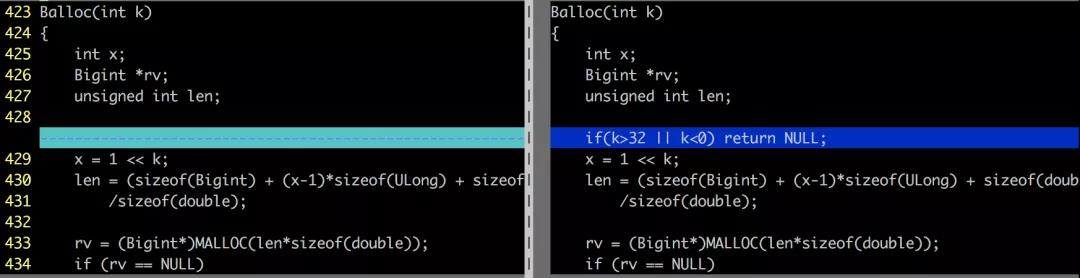
Mesapy(https://github.com/mesalock-linux/mesapy)是基于pypy的内存安全Python解释器。我们结合多种形式验证工具smack[6], seahorn[7] 和 TIS[5]对Mesapy backend的C库函数(共计5044行代码)进行了验证,发现并修补了包括空指针引用,整数溢出等14处程序缺陷。下面是在验证过程中发现的安全缺陷案例。
示例1:空指针引用
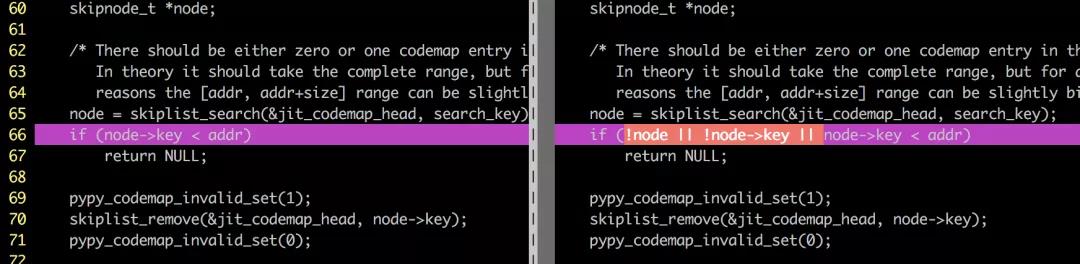
示例2:整数溢出
三. 形式化验证实践经验分享
虽然形式化验证方法能够检测和消除安全缺陷,但具体应用时也存在局限和需要考量的地方。主要体现在如下几个方面:
3.1 分析时间和分析精度的取舍
正如前文反复提及,程序验证任务不仅需要保证很高的精度,也要保证分析任务在合理时间内结束。在实际验证过程中,我们发现对于一些验证目标,设定较低的State Level和State Split策略,并不会对分析精度产生任何影响。而对于一些非常耗时的验证目标,通过调整上述两个参数,能够在理想的分析时间内结束,再辅以少量的人工确认,也能够实现验证目标。
此外,如果确定验证耗时是在特定的子函数上,可以对这个子函数写Function Contract,并且在验证时使用Contract,也能够提升分析效率。但如前文所述,给函数写Contract需要确保对函数语义完全的理解,否则会适得其反。
另外为了提升分析效率,我们也可以对耗时的子函数进行改写。例如下面的例子:

假设分析children函数非常耗时,通过函数定义发现它会通过参数返回两个int,那么我们可以用Interval去改写。如果能够验证y和z在所有可能取值情况下是正确的,那么在它们各自真实取值情况下也一定是正确的。

3.2 需要适量人工参与
形式化验证很难全自动完成。受限于要验证约束条件的复杂程度和证明器的验证求解能力,有些验证约束条件无法验证,以Undefined Behavior的形式报告出来,此时需要人工确认这些是否是真正的安全缺陷。这一步的工作量会与分析策略的设定有关,分析粒度越大,此步骤需要人工参与的工作可能越少。此外,Over-approximation也有可能引入误报,也需要人工参与剔除掉这部分误报。
3.3 测试用例影响验证质量
验证效果也取决于提供的测试用例的质量。编写测试用例的原则是尽可能提升分支验证的覆盖率。总体而言,在编写测试用例时可以用Interval来为参数赋值,覆盖它所有可能取值,这种方式也有助于提升代码验证覆盖率。对于具有复杂类型的参数(例如结构体变量中嵌套包含其他的结构体),有时也需要结合函数实现逻辑,来决定哪些变量需要赋值为Interval、哪些可以保留Concrete赋值,因为并不是所有变量都使用Interval就一定能带来最好的验证效果,Interval推演计算会对分析时间带来显著的开销,延长分析时间。
3.4 验证给与的保障
最后需要说明的是,实践中采用的形式化验证,并不能保证验证过的程序不存在任何安全缺陷——它能够保证的是,对于特定的验证对象(特定版本目标代码,和特定版本依赖库),验证给定的测试样例所能触发的代码,一定不会存在指定验证策略(例如缓冲区溢出检查、整数溢出检查等等)所约束的安全问题。但凡”软件被形式化验证过,所以绝对不会出任何安全问题“的声明,都是夸大、不严谨的。
总结
本文诠释了形式化验证的原理,分享了MesaTEE对实际工程项目进行形式化验证的经验,特别是对TPM核心软件栈和MesaPy C backend的验证。为了让业界少走弯路,我们列举了采用形式化验证需要考量的问题。实践证明,通过形式化验证来保证代码安全虽然成本昂贵,但通过精心设计还是切实可行的。相比于利用静态分析或动态测试的方案来评估程序安全性,形式化验证还是能够更透彻地发现程序安全缺陷,并且保障程序在给定约束下是安全的。
作者:王明华,冯倩,张煜龙,韦韬
[1]. Abstract Interpretation: http://www.cs.utexas.edu/~isil/cs389L/AI-6up.pdf
[2]. A gentle introduction to formal verification of computer systems by abstract interpretation. https://www.di.ens.fr/~cousot/publications.www/CousotCousot-Marktoberdorf-2009.pdf
[3]. Abstract Interpretation and Abstract Domains. http://www.dsi.unive.it/~avp/domains.pdf
[4]. ACSL Mini-Tutorial. https://frama-c.com/download/acsl-tutorial.pdf
[5] Weakest Precondition. https://en.wikipedia.org/wiki/Predicate_transformer_semantics
[6]. TIS. https://trust-in-soft.com
[7]. Smack. https://github.com/smackers/smack
[8]. Seahorn. http://seahorn.github.io
更多内容请移步: